In the last article we saw some testing of the simplest autoregressive model AR(1). I still have an outstanding issue raised by one commenter relating to the hypothesis testing that was introduced, and I hope to come back to it at a later stage.
Different Noise Types
Before we move onto more general AR models, I did do some testing of the effectiveness of the hypothesis test for AR(1) models with different noise types.
The testing shown in Part Four has Gaussian noise (a “normal distribution”), and the theory applied is only apparently valid for Gaussian noise, so I tried uniform distribution of noise and also a Gamma noise distribution:

Figure 1
The Gaussian and uniform distribution produce the same results. The Gamma noise result isn’t shown because it was also the same.
A Gamma distribution can be quite skewed, which was why I tried it – here is the Gamma distribution that was used (with the same variance as the Gaussian, and shifted to produce the same mean = 0):

Figure 2
So in essence I have found that the tests work just as well when the noise component is uniformly distributed or Gamma distributed as when it has a Gaussian distribution (normal distribution).
Hypothesis Testing of AR(1) Model When the Model is Actually AR(2)
The next idea I was interested to try was to apply the hypothesis testing from Part Three on an AR(2) model, when we assume incorrectly that it is an AR(1) model.
Remember that the hypothesis test is quite simple – we produce a series with a known mean, extract a sample, and then using the sample find out how many times the test rejects the hypothesis that the mean is different from its actual value:

Figure 3
As we can see, the test, which should be only rejecting 5% of the tests, rejects a much higher proportion as φ2 increases. This simple test is just by way of introduction.
Higher Order AR Series
The AR(1) model is very simple. As we saw in Part Three, it can be written as:
xt – μ = φ(xt-1 – μ) + εt
where xt = the next value in the sequence, xt-1 = the last value in the sequence, μ = the mean, εt = random quantity and φ = auto-regression parameter
[Minor note, the notation is changed slightly from the earlier article]
In non-technical terms, the next value in the series is made up of a random element plus a dependence on the last value – with the strength of this dependence being the parameter φ.
The more general autoregressive model of order p, AR(p), can be written as:
xt – μ = φ1(xt-1 – μ) + φ2(xt-2 – μ) + .. + φp(xt-p – μ) + εt
φ1..φp = the series of auto-regression parameters
In non-technical terms, the next value in the series is made up of a random element plus a dependence on the last few values. So of course, the challenge is to determine the order p, and then the parameters φ1..φp
There is a bewildering array of tests that can be applied, so I started simply. With some basic algebraic manipulation (not shown – but if anyone is interested I will provide more details in the comments), we can produce a series of linear equations known as the Yule-Walker equations, which allow us to calculate φ1..φp from the estimates of the autoregression.
If you look back to Figure 2 in Part Three you see that by regressing the time series with itself moved by k time steps we can calculate the lag-k correlation, rk, for k=1, 2, 3, etc. So we estimate r1, r2, r3, etc., from the sample of data that we have, and then solve the Yule-Walker equations to get φ1..φp
First of all I played around with simple AR(2) models. The results below are for two different sample sizes.
A population of 90,000 is created (actually 100,000 then the first 10% is deleted), and then a sample is randomly selected 10,000 times from this population. For each sample, the Yule-Walker equations are solved (each of 10,000 times) and then the results are averaged.
In these results I normalized the mean and standard deviation of the parameters by the original values (later I decided that made it harder to see what was going on and reverted to just displaying the actual sample mean and sample standard deviation):

Figure 4
Notice that the sample size of 1,000 produces very accurate results in the estimation of φ1 & φ2, with a small spread. The sample size of 50 appears to produce a low bias in the calculated results, especially for φ2, which is no doubt due to not reading the small print somewhere..
Here is a histogram of the results, showing the spread across φ1 & φ2 – note the values on the axes, the sample size of 1000 produces a much tighter set of results, the sample size of 50 has a much wider spread:

Figure 5
Then I played around with a more general model. With this model I send in AR parameters to create the population, but can define a higher order of AR to test against, to see how well the algorithm estimates the AR parameters from the samples.
In the example below the population is created as AR(3), but tested as if it might be an AR(4) model. The AR(3) parameters (shown on the histogram in the figure below) are φ1= 0.4, φ2= 0.2, φ3= -0.3.
The estimation seems to cope quite well as φ4 is estimated at about zero:

Figure 6
The histogram of results for the first two parameters, note again the difference in values on the axes for the different sample sizes:

Figure 7
[The reason for the finer detail on this histogram compared with figure 5 is just discovery of the Matlab parameters for 3d histograms].
Rotating the histograms around in 3d appears to confirm a bell-curve. Something to test formally at a later stage.
Here’s an example of a process which is AR(5) with φ1= 0.3, φ2= 0, φ3= 0, φ4= 0, φ5= 0.4; tested against AR(6):

Figure 8
And the histogram of estimates of φ1& φ2:

Figure 8
ARMA
We haven’t yet seen ARMA models – auto-regressive moving average models. And we haven’t seen MA models – moving average models with no auto-regressive behavior.
What is an MA or “moving average” model?
The term in the moving average is a “linear filter” on the random elements of the process. So instead of εt as the “uncorrelated noise” in the AR model we have εt plus a weighted sum of earlier random elements. The MA process, of order q, can be written as:
xt – μ = εt + θ1εt-1+ θ2εt-2 + .. + θpεt-p
θ1..θp = the series of moving average parameters
The term “moving average” is a little misleading, as Box and Jenkins also comment.
Why is it misleading?
Because for AR (auto-regressive) and MA (moving average) and ARMA (auto-regressive moving average = combination of AR & MA) models the process is stationary.
This means, in non-technical terms, that the mean of the process is constant through time. That doesn’t sound like “moving average”.
So think of “moving average” as a moving average (filter) of the random elements, or noise, in the process. By their nature these will average out over time (because if the average of the random elements = 0, the average of the moving average of the random elements = 0).
An example of this in the real world might be a chemical introduced randomly into a physical process – this is the εt term – but because the chemical gets caught up in pipework and valves, the actual value of the chemical released into the process at time t is the sum of a proportion of the current value released plus a proportion of earlier values released. Examples of the terminology used for the various processes:
- AR(3) is an autoregressive process of order 3
- MA(2) is a moving average process of order 2
- ARMA(1,1) is a combination of AR(1) and MA(1)
References
Time Series Analysis: Forecasting & Control, 3rd Edition, Box, Jenkins & Reinsel, Prentice Hall (1994)



If anyone can explain why in concept the roots of the “characteristic equation” of the process have to be “outside the unit circle” – for the process to be stationary – I would appreciate it.
A question only for those familiar with the idea of taking an ARMA process and turning the equation into:
φ(B)xt = θ(B)εt
where εt is the noise at time t, xt is the value of the process at time t, and the “characteristic equation”:
φ(B) = 1 – Bφ1 – B2φ2..
where B is the operator that turns xt into xt-1.
Conceptually I would describe the idea as follows:
In case of AR(n) future values depend the more on the earlier ones the larger the absolute value of the root of the characteristic equation is. For values less than one we have a converging behavior while values larger than one make specific sequences of values lead to amplification and blowout.
The case of MA(n) is in a sense inverse to AR(n) (also formally under proper conditions). In that case the characteristic equation does not tell explicitly how the future values depend on the earlier ones, but set constraints for their values. The larger the roots are, the stronger the constraints on future values relative to the earlier ones. Any root less than one tells about a wormhole through which the process can go blowing out while it goes. If all roots are larger than one then no wormholes can exist.
SoD,
Something you might want to look at is the behavior of the variance with sample size a la Koutsoyiannis. You create non-overlapping averages with increasing numbers of samples, k, and plot the standard deviation of the averages versus ln(k) (or maybe log(k)). White noise has a slope of -0.5 everywhere. Auto-regressive noise has an initial slope of nearly zero, at least for AR coefficients << 1, but eventually falls off to -0.5 at large k. For an AR coefficient = 1, the slope may be +0.5. Fractionally integrated noise for d ≤ 0.5, has a constant slope at all time scales, if I remember correctly. Extrapolating the -0.5 slope back to k=1 should give the true standard deviation. Maybe. I’m not completely sure.
A quick attempt at an answer. For a (stochastic) process to be stationary its properties must be invariant with respect to time (roughly speaking). So we need constant mean and variance over time and covariances only dependent on how far apart the terms are. That essentially means all the time dependent bits have to die away. This depends on phi(B). If you factorise the polynomial you get different types of solution depending on whether the vale of the roots of the characteristic equation. Stationarity requires that the real roots be less than one in absolute value, which gives smooth convergence to zero, and there is a similar condition for the complex case which leads to damped cyclical solutions which eventually converge to zero. These conditions can be put into one condition in the complex plane, that the roots have to be outside the unit circle. If the roots are on inside the unit cycle you get explosive behaviour, so you can’t get stationarity. And if one or more of the roots lies on the unit circle you also don’t get stationarity, but you can get stationarity by differencing the series (perhaps more than once). This is, of course the unit root case.
In the simple AR1 case the condition just requires that the autoregressive coefficient is lees than one in absolute value, and the unit root case is the random walk where the coefficient is equal to one.
If you don’t have stationarity most of the standard statistical techniques are invalid.
A good straightforward account can be found here (note that what you call B he calls L).
Click to access fe1.pdf
In the case of time or spatial series, stationarity can also be described as a constraint on the kind of dependency between two points. In the case of time series, for example, the dependency between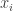 and
and 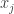 only depends upon
only depends upon  , the distance between them. Similarly, in stationary spatial processes, the dependency only depends upon the distance between the two points, in some mathematically well-defined meaning of distance, e.g., square root of some inner product of the positions between them.
, the distance between them. Similarly, in stationary spatial processes, the dependency only depends upon the distance between the two points, in some mathematically well-defined meaning of distance, e.g., square root of some inner product of the positions between them.
In the case of the unit root question, this can be seen by considering a simplified form of discretized recurrence equation. Suppose you have a process which occurs in successive time steps, . Further, it is described by
. Further, it is described by 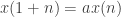 , with
, with  being a non-zero constant. Let’s restrict it to
being a non-zero constant. Let’s restrict it to  . Further, for illustration, suppose
. Further, for illustration, suppose 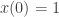 , although it could be any non-zero quantity. Consider what happens with different ranges for
, although it could be any non-zero quantity. Consider what happens with different ranges for  . If
. If 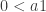 each successive value of
each successive value of  gets bigger and bigger, and the recurrence is unstable, or “blows up”.
gets bigger and bigger, and the recurrence is unstable, or “blows up”.  can be thought of as the distance from the center of the unit circle of roots.
can be thought of as the distance from the center of the unit circle of roots.
Ugh, I was expecting LaTeX to be turned on here. Here’s the reply again without the LaTeX …
In the case of time or spatial series, stationarity can also be described as a constraint on the kind of dependency between two points. In the case of time series, for example, the dependency between x_{i} and x_{j} only depends upon |i-j|, the distance between them. Similarly, in stationary spatial processes, the dependency only depends upon the distance between the two points, in some mathematically well-defined meaning of distance, e.g., square root of some inner product of the positions between them.
In the case of the unit root question, this can be seen by considering a simplified form of discretized recurrence equation. Suppose you have a process which occurs in successive time steps, x(n). Further, it is described by x(1+n) = a x(n), with a being a non-zero constant. Let’s restrict it to a > 0. Further, for illustration, suppose x(0) = 1, although it could be any non-zero quantity. Consider what happens with different ranges for a. If 0 < a 1 each successive value of x(n) gets bigger and bigger, and the recurrence is unstable, or “blows up”. a can be thought of as the distance from the center of the unit circle of roots.
It’s all very interesting to define the difference between stationary and non-stationary processes, but we should remember that in the absence of a non-stationary external forcing, one can make a strong argument that no measure of the climate, such as global average surface temperature, can be non-stationary because there is dissipation in the system.
Take, for example, a classic example of a non-stationary process, a tank where a small volume of water is removed or added randomly. The water level in the tank will be non-stationary. However, to make the example more like the climate, take a tank with a small hole in the bottom. The flow out the bottom will be proportional to the level in the tank. For a constant flow rate into the tank, assuming an infinitely tall tank, there will be a constant level in the tank. Now if we vary the flow into the tank randomly while maintaining a constant average flow, i.e. no non-stationary forcing, the level in the tank will still be a stationary process. The hole in the tank is analogous to the Planck feedback where emission to space is proportional to temperature.
That’s excellent, Mr Payne, and thanks for introducing me to the Fluctuation-Dissipation Theorem!
@DeWitt Payne, so, presumably, GHG emissions constitute a “non-stationary external forcing”.
Over the long term, CO2 emissions, for one, will be stationary because eventually we’ll run out of fossil carbon. Eventually could be quite a long time, though. But CO2 emissions aren’t a random process. We have a fairly good handle on the amount of fossil CO2 released into the atmosphere as well as any change in CO2 from land use/land cover changes. The econometricians that claim that the atmospheric CO2 concentration time series is I(2) while the temperature series is I(1) so you can’t cointegrate them are misapplying the statistical tests. You can’t get a valid result from a unit root test where there is an underlying non-linear deterministic trend. A time series calculated using a cubic polynomial in t, for example, will test as I(2) with drift. Testing for unit roots or fitting an ARIMA model of a series without detrending is assuming the conclusion that there is, in fact, no non-linear underlying deterministic trend.
What I find odd is (a) the insistence upon statistical tests, and (b) the presumption that ARIMA models suffice, because of their distributional assumptions. In fairness, need to admit I’m an unabashed Bayesian, so that will color my views. How, by the way, can you do ARIMA without detrending? I’ve always found that aspect of ARIMA puzzling, because in any nontrivial system, you independently commit to building a trend model of some kind.
How is not the problem. You simply plug the time series into the black box such as the auto.arima function in the R language. Out come numbers. You then can use a Monte Carlo technique to generate a few thousand random series with those numbers and find the 95% confidence limits of the envelope. Then, probably, you claim that there is no significant trend because the confidence limits are nearly wall to wall. In fact, I’m pretty sure that if you do that with the atmospheric CO2 concentration starting around 1900 using relatively recent ice core data plus Mauna Loa data and blindly follow the method, the envelope includes zero, or at least substantial decreases in CO2 concentration are likely. But that didn’t seem to bother the unit root idi0t$ like Beenstock, et. al., 2012. . While checking that reference, I found a paper that totally demolishes their thesis.
You might like to consider Beenstock’s reply here
Click to access esdd-4-C118-2013-supplement.pdf
BTW, everyone can see the components of CO2 increase in the paper from 1990 by Cleveland, Cleveland, McRae, and Terpenning introducing STL. See http://cs.wellesley.edu/~cs315/Papers/stl%20statistical%20model.pdf. That’s extended to non-uniformly spaced series by Eckner at http://www.eckner.com/papers/trend_and_seasonality.pdf. STL is available in an R package.
Regarding Beenstock’s “… Just because greenhouse gas theory explains, for example, why Earth is warmer than it would have been without an atmosphere, does not automatically imply that rising greenhouse gas concentrations must have caused the increase in temperature during the 20th century …”, that just misses the point. Radiative forcing is an experimentally determined phenomenon. Blackbody radiation is an experimentally determined phenomenon. We build lots of equipment which absolutely depends upon these things being true for it to work. Thus, if warming, for some reason, did NOT occur, there would be a need to establish WHY radiative forcing was not having the effect we know it physically must.