There are many classes of systems but in the climate blogosphere world two ideas about climate seem to be repeated the most.
In camp A:
We can’t forecast the weather two weeks ahead so what chance have we got of forecasting climate 100 years from now.
And in camp B:
Weather is an initial value problem, whereas climate is a boundary value problem. On the timescale of decades, every planetary object has a mean temperature mainly given by the power of its star according to Stefan-Boltzmann’s law combined with the greenhouse effect. If the sources and sinks of CO2 were chaotic and could quickly release and sequester large fractions of gas perhaps the climate could be chaotic. Weather is chaotic, climate is not.
Of course, like any complex debate, simplified statements don’t really help. So this article kicks off with some introductory basics.
Many inhabitants of the climate blogosphere already know the answer to this subject and with much conviction. A reminder for new readers that on this blog opinions are not so interesting, although occasionally entertaining. So instead, try to explain what evidence is there for your opinion. And, as suggested in About this Blog:
And sometimes others put forward points of view or “facts” that are obviously wrong and easily refuted. Pretend for a moment that they aren’t part of an evil empire of disinformation and think how best to explain the error in an inoffensive way.
Pendulums
The equation for a simple pendulum is “non-linear”, although there is a simplified version of the equation, often used in introductions, which is linear. However, the number of variables involved is only two:
- angle
- speed
and this isn’t enough to create a “chaotic” system.
If we have a double pendulum, one pendulum attached at the bottom of another pendulum, we do get a chaotic system. There are some nice visual simulations around, which St. Google might help interested readers find.
If we have a forced damped pendulum like this one:
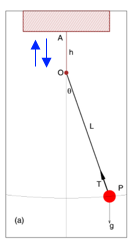
Figure 1 – the blue arrows indicate that the point O is being driven up and down by an external force
-we also get a chaotic system.
What am I talking about? What is linear & non-linear? What is a “chaotic system”?
Digression on Non-Linearity for Non-Technical People
Common experience teaches us about linearity. If I pick up an apple in the supermarket it weighs about 0.15 kg or 150 grams (also known in some countries as “about 5 ounces”). If I take 10 apples the collection weighs 1.5 kg. That’s pretty simple stuff. Most of our real world experience follows this linearity and so we expect it.
On the other hand, if I was near a very cold black surface held at 170K (-103ºC) and measured the radiation emitted it would be 47 W/m². Then we double the temperature of this surface to 340K (67ºC) what would I measure? 94 W/m²? Seems reasonable – double the absolute temperature and get double the radiation.. But it’s not correct.
The right answer is 758 W/m², which is 16x the amount. Surprising, but most actual physics, engineering and chemistry is like this. Double a quantity and you don’t get double the result.
It gets more confusing when we consider the interaction of other variables.
Let’s take riding a bike [updated thanks to Pekka]. Once you get above a certain speed most of the resistance comes from the wind so we will focus on that. Typically the wind resistance increases as the square of the speed. So if you double your speed you get four times the wind resistance. Work done = force x distance moved, so with no head wind power input has to go up as the cube of speed (note 4). This means you have to put in 8x the effort to get 2x the speed.
On Sunday you go for a ride and the wind speed is zero. You get to 25 km/hr (16 miles/hr) by putting a bit of effort in – let’s say you are producing 150W of power (I have no idea what the right amount is). You want your new speedo to register 50 km/hr – so you have to produce 1,200W.
On Monday you go for a ride and the wind speed is 20 km/hr into your face. Probably should have taken the day off.. Now with 150W you get to only 14 km/hr, it takes almost 500W to get to your basic 25 km/hr, and to get to 50 km/hr it takes almost 2,400W. No chance of getting to that speed!
On Tuesday you go for a ride and the wind speed is the same so you go in the opposite direction and take the train home. Now with only 6W you get to go 25 km/hr, to get to 50km/hr you only need to pump out 430W.
In mathematical terms it’s quite simple: F = k(v-w)², Force = (a constant, k) x (road speed – wind speed) squared. Power, P = Fv = kv(v-w)². But notice that the effect of the “other variable”, the wind speed, has really complicated things.
To double your speed on the first day you had to produce eight times the power. To double your speed the second day you had to produce almost five times the power. To double your speed the third day you had to produce just over 70 times the power. All with the same physics.
The real problem with nonlinearity isn’t the problem of keeping track of these kind of numbers. You get used to the fact that real science – real world relationships – has these kind of factors and you come to expect them. And you have an equation that makes calculating them easy. And you have computers to do the work.
No, the real problem with non-linearity (the real world) is that many of these equations link together and solving them is very difficult and often only possible using “numerical methods”.
It is also the reason why something like climate feedback is very difficult to measure. Imagine measuring the change in power required to double speed on the Monday. It’s almost 5x, so you might think the relationship is something like the square of speed. On Tuesday it’s about 70 times, so you would come up with a completely different relationship. In this simple case know that wind speed is a factor, we can measure it, and so we can “factor it out” when we do the calculation. But in a more complicated system, if you don’t know the “confounding variables”, or the relationships, what are you measuring? We will return to this question later.
When you start out doing maths, physics, engineering.. you do “linear equations”. These teach you how to use the tools of the trade. You solve equations. You rearrange relationships using equations and mathematical tricks, and these rearranged equations give you insight into how things work. It’s amazing. But then you move to “nonlinear” equations, aka the real world, which turns out to be mostly insoluble. So nonlinear isn’t something special, it’s normal. Linear is special. You don’t usually get it.
..End of digression
Back to Pendulums
Let’s take a closer look at a forced damped pendulum. Damped, in physics terms, just means there is something opposing the movement. We have friction from the air and so over time the pendulum slows down and stops. That’s pretty simple. And not chaotic. And not interesting.
So we need something to keep it moving. We drive the pivot point at the top up and down and now we have a forced damped pendulum. The equation that results (note 1) has the massive number of three variables – position, speed and now time to keep track of the driving up and down of the pivot point. Three variables seems to be the minimum to create a chaotic system (note 2).
As we increase the ratio of the forcing amplitude to the length of the pendulum (β in note 1) we can move through three distinct types of response:
- simple response
- a “chaotic start” followed by a deterministic oscillation
- a chaotic system
This is typical of chaotic systems – certain parameter values or combinations of parameters can move the system between quite different states.
Here is a plot (note 3) of position vs time for the chaotic system, β=0.7, with two initial conditions, only different from each other by 0.1%:

Forced damped harmonic pendulum, b=0.7: Start angular speed 0.1; 0.1001
Figure 1
It’s a little misleading to view the angle like this because it is in radians and so needs to be mapped between 0-2π (but then we get a discontinuity on a graph that doesn’t match the real world). We can map the graph onto a cylinder plot but it’s a mess of reds and blues.
Another way of looking at the data is via the statistics – so here is a histogram of the position (θ), mapped to 0-2π, and angular speed (dθ/dt) for the two starting conditions over the first 10,000 seconds:
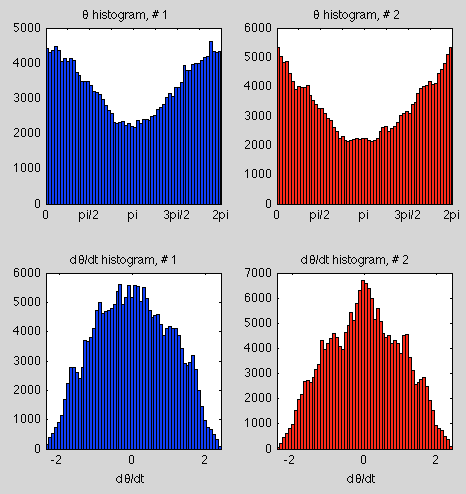
Histograms for 10,000 seconds
Figure 2
We can see they are similar but not identical (note the different scales on the y-axis).
That might be due to the shortness of the run, so here are the results over 100,000 seconds:
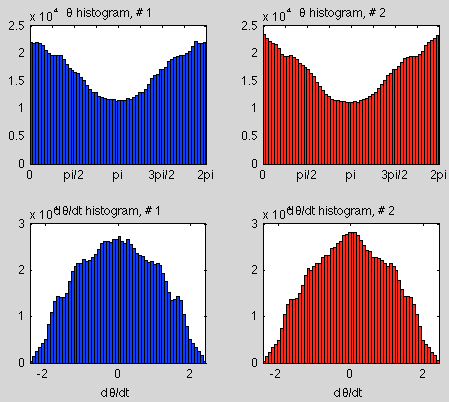
Histogram for 100,000 seconds
Figure 3
As we increase the timespan of the simulation the statistics of two slightly different initial conditions become more alike.
So if we want to know the state of a chaotic system at some point in the future, very small changes in the initial conditions will amplify over time, making the result unknowable – or no different from picking the state from a random time in the future. But if we look at the statistics of the results we might find that they are very predictable. This is typical of many (but not all) chaotic systems.
Orbits of the Planets
The orbits of the planets in the solar system are chaotic. In fact, even 3-body systems moving under gravitational attraction have chaotic behavior. So how did we land a man on the moon? This raises the interesting questions of timescales and amount of variation. Planetary movement – for our purposes – is extremely predictable over a few million years. But over 10s of millions of years we might have trouble predicting exactly the shape of the earth’s orbit – eccentricity, time of closest approach to the sun, obliquity.
However, it seems that even over a much longer time period the planets will still continue in their orbits – they won’t crash into the sun or escape the solar system. So here we see another important aspect of some chaotic systems – the “chaotic region” can be quite restricted. So chaos doesn’t mean unbounded.
According to Cencini, Cecconi & Vulpiani (2010):
Therefore, in principle, the Solar system can be chaotic, but not necessarily this implies events such as collisions or escaping planets..
However, there is evidence that the Solar system is “astronomically” stable, in the sense that the 8 largest planets seem to remain bound to the Sun in low eccentricity and low inclination orbits for time of the order of a billion years. In this respect, chaos mostly manifest in the irregular behavior of the eccentricity and inclination of the less massive planets, Mercury and Mars. Such variations are not large enough to provoke catastrophic events before extremely large time. For instance, recent numerical investigations show that for catastrophic events, such as “collisions” between Mercury and Venus or Mercury failure into the Sun, we should wait at least a billion years.
And bad luck, Pluto.
Deterministic, non-Chaotic, Systems with Uncertainty
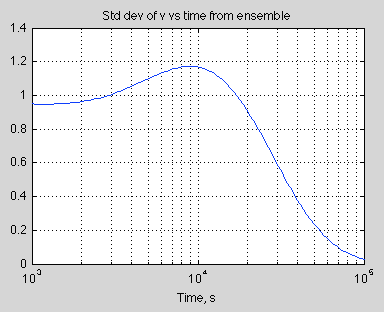
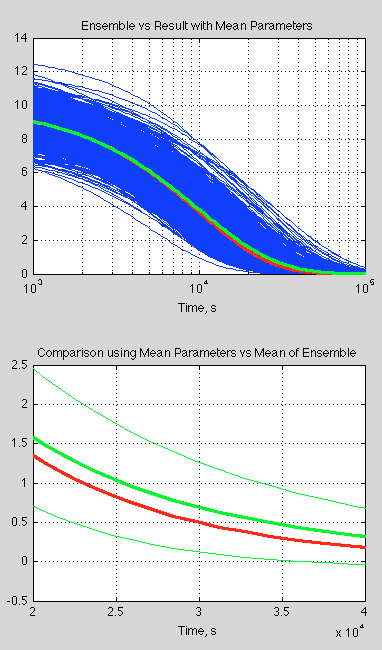
Just to round out the picture a little, even if a system is not chaotic and is deterministic we might lack sufficient knowledge to be able to make useful predictions. If you take a look at figure 3 in Ensemble Forecasting you can see that with some uncertainty of the initial velocity and a key parameter the resulting velocity of an extremely simple system has quite a large uncertainty associated with it.
This case is quantitively different of course. By obtaining more accurate values of the starting conditions and the key parameters we can reduce our uncertainty. Small disturbances don’t grow over time to the point where our calculation of a future condition might as well just be selected from a randomly time in the future.
Transitive, Intransitive and “Almost Intransitive” Systems
Many chaotic systems have deterministic statistics. So we don’t know the future state beyond a certain time. But we do know that a particular position, or other “state” of the system, will be between a given range for x% of the time, taken over a “long enough” timescale. These are transitive systems.
Other chaotic systems can be intransitive. That is, for a very slight change in initial conditions we can have a different set of long term statistics. So the system has no “statistical” predictability. Lorenz 1968 gives a good example.
Lorenz introduces the concept of almost intransitive systems. This is where, strictly speaking, the statistics over infinite time are independent of the initial conditions, but the statistics over “long time periods” are dependent on the initial conditions. And so he also looks at the interesting case (Lorenz 1990) of moving between states of the system (seasons), where we can think of the precise starting conditions each time we move into a new season moving us into a different set of long term statistics. I find it hard to explain this clearly in one paragraph, but Lorenz’s papers are very readable.
Conclusion?
This is just a brief look at some of the basic ideas.
Articles in the Series
Natural Variability and Chaos – One – Introduction
Natural Variability and Chaos – Two – Lorenz 1963
Natural Variability and Chaos – Three – Attribution & Fingerprints
Natural Variability and Chaos – Four – The Thirty Year Myth
Natural Variability and Chaos – Five – Why Should Observations match Models?
Natural Variability and Chaos – Six – El Nino
Natural Variability and Chaos – Seven – Attribution & Fingerprints Or Shadows?
Natural Variability and Chaos – Eight – Abrupt Change
References
Chaos: From Simple Models to Complex Systems, Cencini, Cecconi & Vulpiani, Series on Advances in Statistical Mechanics – Vol. 17 (2010)
Climatic Determinism, Edward Lorenz (1968) – free paper
Can chaos and intransivity lead to interannual variation, Edward Lorenz, Tellus (1990) – free paper
Notes
Note 1 – The equation is easiest to “manage” after the original parameters are transformed so that tω->t. That is, the period of external driving, T0=2π under the transformed time base.
Then:
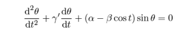
where θ = angle, γ’ = γ/ω, α = g/Lω², β =h0/L;
these parameters based on γ = viscous drag coefficient, ω = angular speed of driving, g = acceleration due to gravity = 9.8m/s², L = length of pendulum, h0=amplitude of driving of pivot point
Note 2 – This is true for continuous systems. Discrete systems can be chaotic with less parameters
Note 3 – The results were calculated numerically using Matlab’s ODE (ordinary differential equation) solver, ode45.
Note 4 – Force = k(v-w)2 where k is a constant, v=velocity, w=wind speed. Work done = Force x distance moved so Power, P = Force x velocity.
Therefore:
P = kv(v-w)2
If we know k, v & w we can find P. If we have P, k & w and want to find v it is a cubic equation that needs solving.
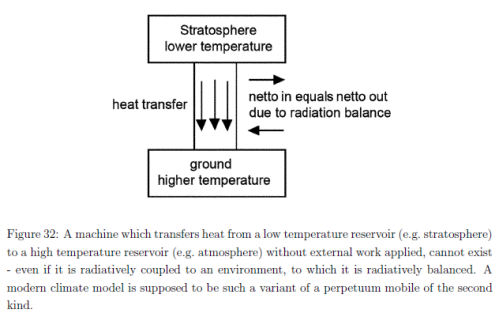


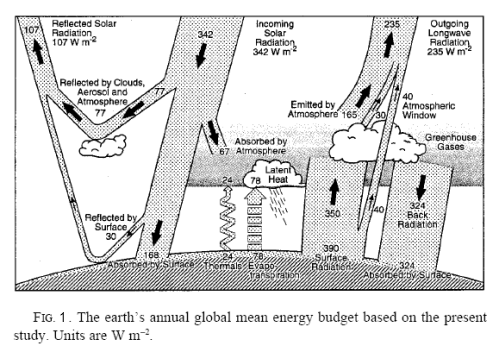



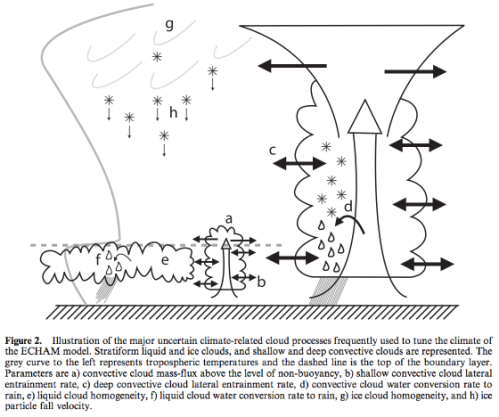
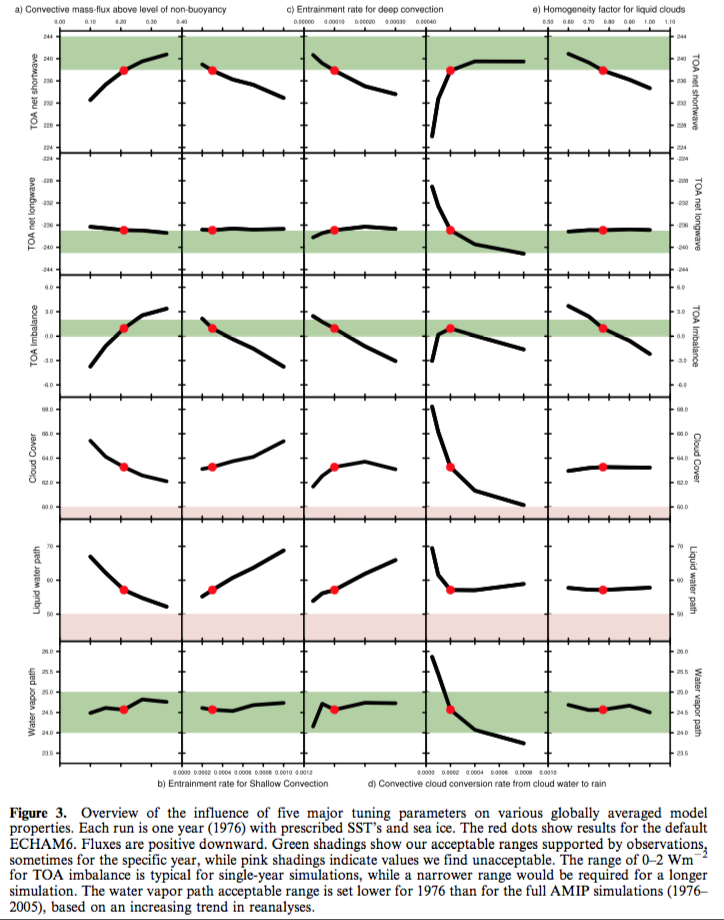




Natural Variability and Chaos – Two – Lorenz 1963
Posted in Atmospheric Physics, Climate Models, Commentary on July 27, 2014| 25 Comments »
In Part One we had a look at some introductory ideas. In this article we will look at one of the ground-breaking papers in chaos theory – Deterministic nonperiodic flow, Edward Lorenz (1963). It has been cited more than 13,500 times.
There might be some introductory books on non-linear dynamics and chaos that don’t include a discussion of this paper – or at least a mention – but they will be in a small minority.
Lorenz was thinking about convection in the atmosphere, or any fluid heated from below, and reduced the problem to just three simple equations. However, the equations were still non-linear and because of this they exhibit chaotic behavior.
Cencini et al describe Lorenz’s problem:
Willem Malkus and Lou Howard of MIT came up with an equivalent system – the simplest version is shown in this video:
Figure 1
Steven Strogatz (1994), an excellent introduction to dynamic and chaotic systems – explains and derives the equivalence between the classic Lorenz equations and this tilted waterwheel.
L63 (as I’ll call these equations) has three variables apart from time: intensity of convection (x), temperature difference between ascending and descending currents (y), deviation of temperature from a linear profile (z).
Here are some calculated results for L63 for the “classic” parameter values and three very slightly different initial conditions (blue, red, green in each plot) over 5,000 seconds, showing the start and end 50 seconds – click to expand:
Figure 2 – click to expand – initial conditions x,y,z = 0, 1, 0; 0, 1.001, 0; 0, 1.002, 0
We can see that quite early on the two conditions diverge, and 5000 seconds later the system still exhibits similar “non-periodic” characteristics.
For interest let’s zoom in on just over 10 seconds of ‘x’ near the start and end:
Figure 3
Going back to an important point from the first post, some chaotic systems will have predictable statistics even if the actual state at any future time is impossible to determine (due to uncertainty over the initial conditions).
So we’ll take a look at the statistics via a running average – click to expand:
Figure 4 – click to expand
Two things stand out – first of all the running average over more than 100 “oscillations” still shows a large amount of variability. So at any one time, if we were to calculate the average from our current and historical experience we could easily end up calculating a value that was far from the “long term average”. Second – the “short term” average, if we can call it that, shows large variation at any given time between our slightly divergent initial conditions.
So we might believe – and be correct – that the long term statistics of slightly different initial conditions are identical, yet be fooled in practice.
Of course, surely it sorts itself out over a longer time scale?
I ran the same simulation (with just the first two starting conditions) for 25,000 seconds and then used a filter window of 1,000 seconds – click to expand:
Figure 5 – click to expand
The total variability is less, but we have a similar problem – it’s just lower in magnitude. Again we see that the statistics of two slightly different initial conditions – if we were to view them by the running average at any one time – are likely to be different even over this much longer time frame.
From this 25,000 second simulation:
Repeat for the data from the other initial condition.
Here is the result:
Figure 6
To make it easier to see, here is the difference between the two sets of histograms, normalized by the maximum value in each set:
Figure 7
This is a different way of viewing what we saw in figures 4 & 5.
The spread of sample means shrinks as we increase the time period but the difference between the two data sets doesn’t seem to disappear (note 2).
Attractors and Phase Space
The above plots show how variables change with time. There’s another way to view the evolution of system dynamics and that is by “phase space”. It’s a name for a different kind of plot.
So instead of plotting x vs time, y vs time and z vs time – let’s plot x vs y vs z – click to expand:
Figure 8 – Click to expand – the colors blue, red & green represent the same initial conditions as in figure 2
Without some dynamic animation we can’t now tell how fast the system evolves. But we learn something else that turns out to be quite amazing. The system always end up on the same “phase space”. Perhaps that doesn’t seem amazing yet..
Figure 7 was with three initial conditions that are almost identical. Let’s look at three initial conditions that are very different: x,y,z = 0, 1, 0; 5, 5, 5; 20, 8, 1:
Figure 9 – Click to expand
Here’s an example (similar to figure 7) from Strogatz – a set of 10,000 closely separated initial conditions and how they separate at 3, 6, 9 and 15 seconds. The two key points:
From Strogatz 1994
Figure 10
A dynamic visualization on Youtube with 500,000 initial conditions:
Figure 11
There’s lot of theory around all of this as you might expect. But in brief, in a “dissipative system” the “phase volume” contracts exponentially to zero. Yet for the Lorenz system somehow it doesn’t quite manage that. Instead, there are an infinite number of 2-d surfaces. Or something. For the sake of a not overly complex discussion a wide range of initial conditions ends up on something very close to a 2-d surface.
This is known as a strange attractor. And the Lorenz strange attractor looks like a butterfly.
Conclusion
Lorenz 1963 reduced convective flow (e.g., heating an atmosphere from the bottom) to a simple set of equations. Obviously these equations are a massively over-simplified version of anything like the real atmosphere. Yet, even with this very simple set of equations we find chaotic behavior.
Chaotic behavior in this example means:
Articles in the Series
Natural Variability and Chaos – One – Introduction
Natural Variability and Chaos – Two – Lorenz 1963
Natural Variability and Chaos – Three – Attribution & Fingerprints
Natural Variability and Chaos – Four – The Thirty Year Myth
Natural Variability and Chaos – Five – Why Should Observations match Models?
Natural Variability and Chaos – Six – El Nino
Natural Variability and Chaos – Seven – Attribution & Fingerprints Or Shadows?
Natural Variability and Chaos – Eight – Abrupt Change
References
Deterministic nonperiodic flow, EN Lorenz, Journal of the Atmospheric Sciences (1963)
Chaos: From Simple Models to Complex Systems, Cencini, Cecconi & Vulpiani, Series on Advances in Statistical Mechanics – Vol. 17 (2010)
Non Linear Dynamics and Chaos, Steven H. Strogatz, Perseus Books (1994)
Notes
Note 1: The Lorenz equations:
dx/dt = σ (y-x)
dy/dt = rx – y – xz
dz/dt = xy – bz
where
x = intensity of convection
y = temperature difference between ascending and descending currents
z = devision of temperature from a linear profile
σ = Prandtl number, ratio of momentum diffusivity to thermal diffusivity
r = Rayleigh number
b = “another parameter”
And the “classic parameters” are σ=10, b = 8/3, r = 28
Note 2: Lorenz 1963 has over 13,000 citations so I haven’t been able to find out if this system of equations is transitive or intransitive. Running Matlab on a home Mac reaches some limitations and I maxed out at 25,000 second simulations mapped onto a 0.01 second time step.
However, I’m not trying to prove anything specifically about the Lorenz 1963 equations, more illustrating some important characteristics of chaotic systems
Note 3: Small differences in initial conditions grow exponentially, until we reach the limits of the attractor. So it’s easy to show the “benefit” of more accurate data on initial conditions.
If we increase our precision on initial conditions by 1,000,000 times the increase in prediction time is a massive 2½ times longer.
Read Full Post »