In Part Three we looked at attribution in the early work on this topic by Hegerl et al 1996. I started to write Part Four as the follow up on Attribution as explained in the 5th IPCC report (AR5), but got caught up in the many volumes of AR5.
And instead for this article I decided to focus on what might seem like an obscure point. I hope readers stay with me because it is important.
Here is a graphic from chapter 11 of IPCC AR5:
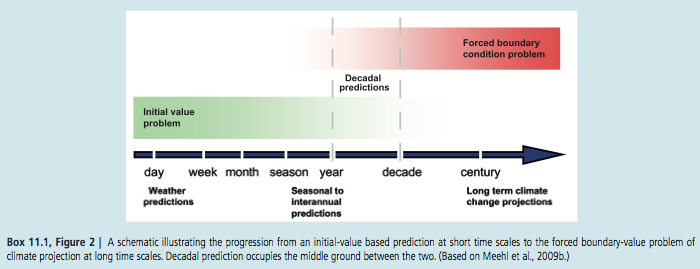
From IPCC AR5 Chapter 11
Figure 1
And in the introduction, chapter 1:
Climate in a narrow sense is usually defined as the average weather, or more rigorously, as the statistical description in terms of the mean and variability of relevant quantities over a period of time ranging from months to thousands or millions of years. The relevant quantities are most often surface variables such as temperature, precipitation and wind.
Classically the period for averaging these variables is 30 years, as defined by the World Meteorological Organization.
Climate in a wider sense also includes not just the mean conditions, but also the associated statistics (frequency, magnitude, persistence, trends, etc.), often combining parameters to describe phenomena such as droughts. Climate change refers to a change in the state of the climate that can be identified (e.g., by using statistical tests) by changes in the mean and/or the variability of its properties, and that persists for an extended period, typically decades or longer.
[Emphasis added].
Weather is an Initial Value Problem, Climate is a Boundary Value Problem
The idea is fundamental, the implementation is problematic.
As explained in Natural Variability and Chaos – Two – Lorenz 1963, there are two key points about a chaotic system:
- With even a minute uncertainty in the initial starting condition, the predictability of future states is very limited
- Over a long time period the statistics of the system are well-defined
(Being technical, the statistics are well-defined in a transitive system).
So in essence, we can’t predict the exact state of the future – from the current conditions – beyond a certain timescale which might be quite small. In fact, in current weather prediction this time period is about one week.
After a week we might as well say either “the weather on that day will be the same as now” or “the weather on that day will be the climatological average” – and either of these will be better than trying to predict the weather based on the initial state.
No one disagrees on this first point.
In current climate science and meteorology the term used is the skill of the forecast. Skill means, not how good is the forecast, but how much better is it than a naive approach like, “it’s July in New York City so the maximum air temperature today will be 28ºC”.
What happens in practice, as can be seen in the simple Lorenz system shown in Part Two, is a tiny uncertainty about the starting condition gets amplified. Two almost identical starting conditions will diverge rapidly – the “butterfly effect”. Eventually these two conditions are no more alike than one of the conditions and a time chosen at random from the future.
The wide divergence doesn’t mean that the future state can be anything. Here’s an example from the simple Lorenz system for three slightly different initial conditions:
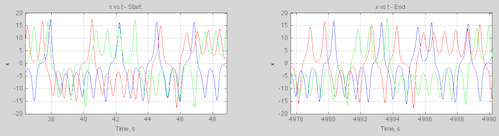
Figure 2
We can see that the three conditions that looked identical for the first 20 seconds (see figure 2 in Part Two) have diverged. The values are bounded but at any given time we can’t predict what the value will be.
On the second point – the statistics of the system, there is a tiny hiccup.
But first let’s review what is agreed upon. Climate is the statistics of weather. Weather is unpredictable more than a week ahead. Climate, as the statistics of weather, might be predictable. That is, just because weather is unpredictable, it doesn’t mean (or prove) that climate is also unpredictable.
This is what we find with simple chaotic systems.
So in the endeavor of climate modeling the best we can hope for is a probabilistic forecast. We have to run “a lot” of simulations and review the statistics of the parameter we are trying to measure.
To give a concrete example, we might determine from model simulations that the mean sea surface temperature in the western Pacific (between a certain latitude and longitude) in July has a mean of 29ºC with a standard deviation of 0.5ºC, while for a certain part of the north Atlantic it is 6ºC with a standard deviation of 3ºC. In the first case the spread of results tells us – if we are confident in our predictions – that we know the western Pacific SST quite accurately, but the north Atlantic SST has a lot of uncertainty. We can’t do anything about the model spread. In the end, the statistics are knowable (in theory), but the actual value on a given day or month or year are not.
Now onto the hiccup.
With “simple” chaotic systems that we can perfectly model (note 1) we don’t know in advance the timescale of “predictable statistics”. We have to run lots of simulations over long time periods until the statistics converge on the same result. If we have parameter uncertainty (see Ensemble Forecasting) this means we also have to run simulations over the spread of parameters.
Here’s my suggested alternative of the initial value vs boundary value problem:
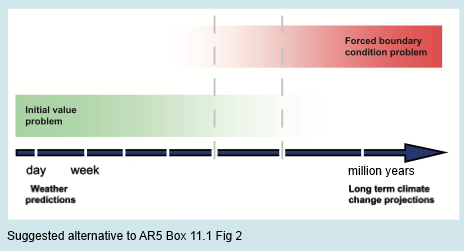
Figure 3
So one body made an ad hoc definition of climate as the 30-year average of weather.
If this definition is correct and accepted then “climate” is not a “boundary value problem” at all. Climate is an initial value problem and therefore a massive problem given our ability to forecast only one week ahead.
Suppose, equally reasonably, that the statistics of weather (=climate), given constant forcing (note 2), are predictable over a 10,000 year period.
In that case we can be confident that, with near perfect models, we have the ability to be confident about the averages, standard deviations, skews, etc of the temperature at various locations on the globe over a 10,000 year period.
Conclusion
The fact that chaotic systems exhibit certain behavior doesn’t mean that 30-year statistics of weather can be reliably predicted.
30-year statistics might be just as dependent on the initial state as the weather three weeks from today.
Articles in the Series
Natural Variability and Chaos – One – Introduction
Natural Variability and Chaos – Two – Lorenz 1963
Natural Variability and Chaos – Three – Attribution & Fingerprints
Natural Variability and Chaos – Four – The Thirty Year Myth
Natural Variability and Chaos – Five – Why Should Observations match Models?
Natural Variability and Chaos – Six – El Nino
Natural Variability and Chaos – Seven – Attribution & Fingerprints Or Shadows?
Natural Variability and Chaos – Eight – Abrupt Change
Notes
Note 1: The climate system is obviously imperfectly modeled by GCMs, and this will always be the case. The advantage of a simple model is we can state that the model is a perfect representation of the system – it is just a definition for convenience. It allows us to evaluate how slight changes in initial conditions or parameters affect our ability to predict the future.
The IPCC report also has continual reminders that the model is not reality, for example, chapter 11, p. 982:
For the remaining projections in this chapter the spread among the CMIP5 models is used as a simple, but crude, measure of uncertainty. The extent of agreement between the CMIP5 projections provides rough guidance about the likelihood of a particular outcome. But — as partly illustrated by the discussion above — it must be kept firmly in mind that the real world could fall outside of the range spanned by these particular models.
[Emphasis added].
Chapter 1, p.138:
Model spread is often used as a measure of climate response uncertainty, but such a measure is crude as it takes no account of factors such as model quality (Chapter 9) or model independence (e.g., Masson and Knutti, 2011; Pennell and Reichler, 2011), and not all variables of interest are adequately simulated by global climate models..
..Climate varies naturally on nearly all time and space scales, and quantifying precisely the nature of this variability is challenging, and is characterized by considerable uncertainty.
I haven’t yet been able to determine how these firmly noted and challenging uncertainties have been factored into the quantification of 95-100%, 99-100%, etc, in the various chapters of the IPCC report.
Note 2: There are some complications with defining exactly what system is under review. For example, do we take the current solar output, current obliquity,precession and eccentricity as fixed? If so, then any statistics will be calculated for a condition that will anyway be changing. Alternatively, we can take these values as changing inputs in so far as we know the changes – which is true for obliquity, precession and eccentricity but not for solar output.
The details don’t really alter the main point of this article.


