In Part Five – More on Tuning & the Magic Behind the Scenes and also in the earlier Part Four we looked at the challenge of selecting parameters in climate models. A recent 2017 paper on this topic by Frédéric Hourdin and colleagues is very illuminating. One of the co-authors is Thorsten Mauritsen, the principal author of the 2012 paper we reviewed in Part Four. Another co-author is Jean-Christophe Golaz, the principal author of the 2013 paper we reviewed in Part Five.
The topics are similar but there is some interesting additional detail and commentary. The paper is open and, as always, I recommend reading the whole paper.
One of the key points is that climate models need to be specific about their “target” – were they trying to get the model to match recent climatology? top of atmosphere radiation balance? last 100 years of temperature trends? If we know that a model was developed with an eye on a particular target then it doesn’t demonstrate model skill if they get that target right.
Because of the uncertainties in observations and in the model formulation, the possible parameter choices are numerous and will differ from one modeling group to another. These choices should be more often considered in model intercomparison studies. The diversity of tuning choices reflects the state of our current climate understanding, observation, and modeling. It is vital that this diversity be maintained. It is, however, important that groups better communicate their tuning strategy. In particular, when comparing models on a given metric, either for model assessment or for understanding of climate mechanisms, it is essential to know whether some models used this metric as tuning target.
They comment on the paper by Jeffrey Kiehl from 2007 (referenced in The Debate is Over – 99% of Scientists believe Gravity and the Heliocentric Solar System so therefore..) which showed how models with higher sensitivity to CO2 have higher counter-balancing negative forcing from aerosols.
And later in the paper:
The question of whether the twentieth-century warming should be considered a target of model development or an emergent property is polarizing the climate modeling community, with 35% of modelers stating that twentieth-century warming was rated very important to decisive, whereas 30% would not consider it at all during development.
Some view the temperature record as an independent evaluation dataset not to be used, while others view it as a valuable observational constraint on the model development. Likewise, opinions diverge as to which measures, either forcing or ECS, are legitimate means for improving the model match to observed warming.
The question of developing toward the twentieth- century warming therefore is an area of vigorous debate within the community..
..The fact that some models are explicitly, or implicitly, tuned to better match the twentieth-century warming, while others may not be, clearly complicates the interpretation of the results of combined model ensembles such as CMIP. The diversity of approaches is unavoidable as individual modeling centers pursue their model development to seek their specific scientific goals.
It is, however, essential that decisions affecting forcing or feedback made during model development be transparently documented.
And so, onto another recent paper by Sumant Nigam and colleagues. They review the temperature trends by season over the last 100 years and review that against models. They look only at the northern hemisphere over land, due to the better temperature dataset available (compared with the southern hemisphere).
Here are the observations of the trends for each of the four seasons, I find it fascinating to see the difference between the seasonal trends:
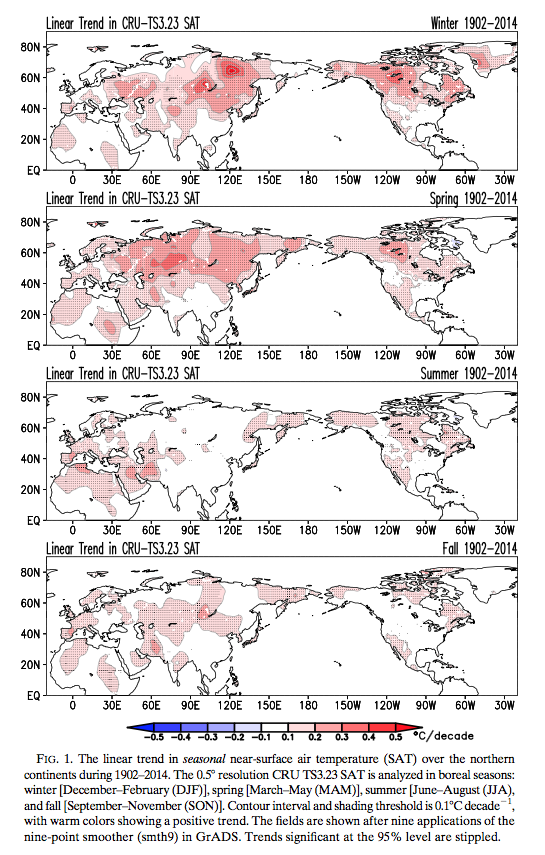
From Nigam et al 2017
Figure 1 – Click to enlarge
Then they compare the observations to some of the models used in IPCC AR5 (from the model intercomparison project, CMIP5) – top line is observations, each line below is a different model. When we compare the geographical distribution of winter-summer trend (right column) we can see that the models don’t do very well:
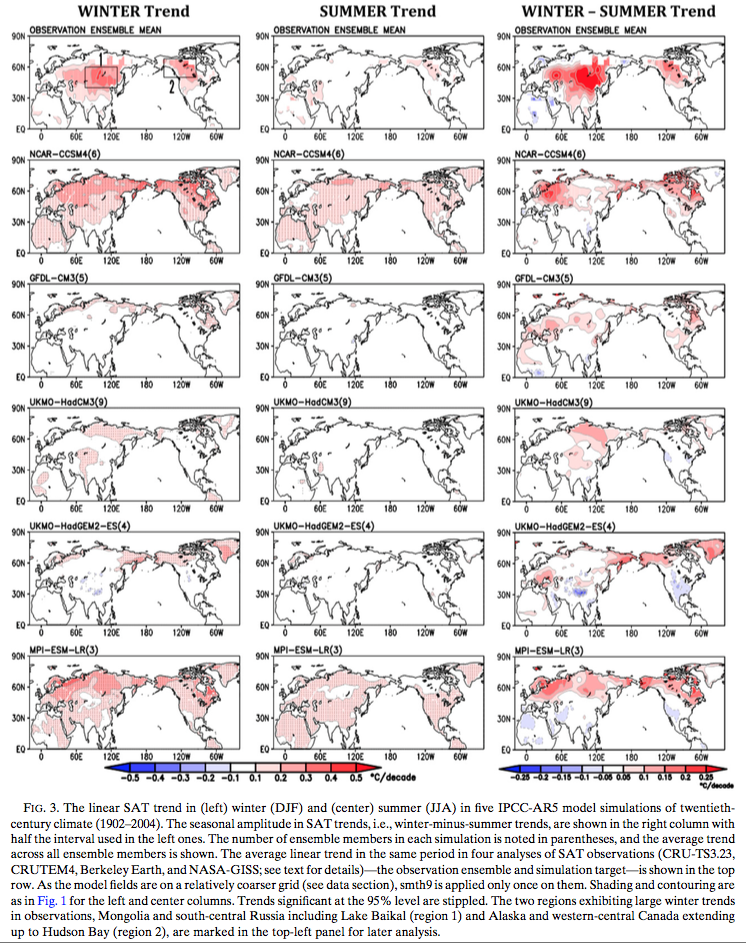
From Nigam et al 2017
Figure 2 – Click to enlarge
From their conclusion:
The urgent need for shifting the evaluative and diagnostic focus away from the customary annual mean toward the seasonal cycle of secular warming is manifest in the inability of the leading climate models (whose simulations inform the IPCC’s Fifth Assessment Report) to generate realistic and robust (large signal-to noise ratio) twentieth-century winter and summer SAT trends over the northern continents. The large intra-ensemble SD of century-long SAT trends in some IPCC AR5 models (e.g., GFDL-CM3) moreover raises interesting questions: If this subset of climate models is realistic, especially in generation of ultra-low-frequency variability, is the century-long (1902–2014) linear trend in observed SAT—a one-member ensemble of the climate record—a reliable indicator of the secular warming signal?
I’ve commented a number of times in various articles – people who don’t read climate science papers often have some idea that climate scientists are monolithically opposed to questioning model results or questioning “the orthodoxy”. This is contrary to what you find if you read lots of papers. It might be that press releases that show up in The New York Times, CNN or the BBC (or pick another ideological bellwether) have some kind of monolithic sameness but this just demonstrates that no one interested in finding out anything important (apart from the weather and celebrity news) should ever watch/read media outlets.
They continue:
The relative contribution of both mechanisms to the observed seasonality in century-long SAT trends needs further assessment because of uncertainties in the diagnosis of evapotranspiration and sea level pressure from the century-long observational records. Climate system models—ideal tools for investigation of mechanisms through controlled experimentation—are unfortunately not yet ready given their inability to simulate the seasonality of trends in historical simulations.
Subversive indeed.
Their investigation digs into evapotranspiration – the additional water vapor, available from plants, to be evaporated and therefore to remove heat from the surface during the summer months.
Conclusion
“All models are wrong but some are useful” – a statement attributed to a modeler from a different profession (statistical process control) and sometimes quoted also by climate modelers.
This is always a good way to think about models. Perhaps the inability of climate models to reproduce seasonal trends is inconsequential – or perhaps it is important. Models fail on many levels. The question is why, and the answers lead to better models.
Climate science is a real science, contrary to the claims of many people who don’t read much climate science papers, because many published papers ask important and difficult questions, and critique the current state of the science. That is, falsifiability is being addressed. These questions might not become media headlines, or even make it into the Summary for Policymakers in IPCC reports, but papers with these questions are not outliers.
I found both of these papers very interesting. Hourdin et al because they ask valuable questions about how models are tuned, and Nigam et al because they point out that climate models do a poor job of reproducing an important climate trend (seasonal temperature) which provides an extra level of testing for climate models.
References
Striking Seasonality in the Secular Warming of the Northern Continents: Structure and Mechanisms, Sumant Nigam et al, Journal of Climate (2017)
The Art and Science of Climate Model Tuning, Frédéric Hourdin et al, American Meteorological Society (2017) – free paper



I’m not sure that what they’ve done represents the issues well, although I’m only going on the quotes and your presentation here rather than the full paper. For one thing, unless I’m missing something they seem to have made the old mistake of comparing model ensemble means with individual realisations (i.e. observations). When you’re looking at not just regional but also seasonal trends natural variability can have a big influence even on a centennial scale. For example, within the highlighted Central Asian area I found 1902-2004 Winter trends across the 5 GFDL-CM3 realisations varying from -0.07K/Decade to +0.16K/Decade.
The goal of the overall modelling enterprise (rather than the goal of individual modelling groups) is that the CMIP5/CMIP6/CMIPn ensemble properly represents the range of possible trends. We wouldn’t and shouldn’t expect each model run to precisely reproduce what actually happens/happened, especially at seasonal and regional scales.
I think van Oldenborgh et al. 2013 provides a more useful basis for analysing regional simulation within global models, albeit not based on seasonal trend differences.
paulski0,
I’ve read van Oldenborgh et al. 2013 before, and now I’ve just reread it.
It’s a good paper, and here is what I think it is saying – please let me know if you agree:
1. With weather forecasting we have lots of forecast v observations to compare. For example, every week we have a forecast ensemble that might say “10% chance of severe storm in this region”, “40% change of rain” and so on.
So we look at how often the various items occurred and compare it with the probabilities the forecast gave.
This helps us see if the forecast is skewed – if the “10% events” only occurred 2% of the time then the model is over-estimating these probabilities.
2. We can’t do that with climate forecasts because we are running one long experiment.
We have lots of model results (like with weather forecasting) but one observation.
So instead we will detrend the global temperature change from the observations and models, break the globe up into a grid so that we have y observations.
For each observation we say “where in the spread of model results did it come? around 0 – 5%? between 5-10%? etc.
3. Now we compare – How often did we get the “0-5%”? It should be only 5% of the time. Oh, we got it 15% of the time. How often did we get the observation in the 95-100% of model spread? Oh, we got it 20% of the time.
So, conclusion, models don’t do a good job of spatial trends vs observations – they are too close to the average trend, whereas actual observations vary much more.
This is how I see the paper. Let me know your thoughts.
Yes, that fits my reading.
Here’s a few more details from the paper.
Model details:
Observations:
And the graphic of each series:
Click to expand
The mean and sd of two ensembles for winter:
Click to enlarge
GFDL mean at the top, individual runs below:
paulski0,
I posted a bit more from the paper for reference.
I think it would be very interesting to see the van Oldenborgh approach used on each season.
But I can’t see find a way mentally to come up with the idea that the model is correctly representing the seasonal trends.
If we applied this approach and found that the model was not underpredicting variation, or only underpredicting it as much as models currently do for the annual average trends (as in van Oldenborgh) I would be surprised. And how would this happen? I can only picture it happening by some geographically biased dispersion of results.
Interested in your comments.
In the meantime I will contact the lead author and ask for his thoughts.
My other main comment is that if models cannot reproduce 100 year trends at regional scales then “downscaling” (higher resolution regional modeling based on the output of global GCMs) is probably a fairly useless exercise. I have some thoughts on another article on this subject.
Thanks for the extra info. Looks like they did pay attention to individual model realisations and note that some do get close to observations.
But I can’t see find a way mentally to come up with the idea that the model is correctly representing the seasonal trends.
If we applied this approach and found that the model was not underpredicting variation, or only underpredicting it as much as models currently do for the annual average trends (as in van Oldenborgh) I would be surprised. And how would this happen? I can only picture it happening by some geographically biased dispersion of results.
Sorry, I’m not clear what you’re saying here. Are you talking about whether applying the van Oldenborgh approach to seasonal trends would find the same variability underprediction as for annual? Yes, I suspect that would be the case.
On the downscaling, I think that’s partly what motivated van Oldenborgh et al. but it’s not an area I’m familiar with at all so can’t really comment.
SoD,
Thanks for another interesting post. You wrote:” Models fail on many levels. The question is why, and the answers lead to better models.”
.
Except that doesn’t really seem to happen… the crazy-high sensitivity models are not revised to be closer to reality… they remain crazy-high in sensitivity… while the merely high sensitivity models appear static in their projections, even when their many failings are pointed out. A cynic might guess that the motivation is a desire in the climate science community (conscious or not) for the modeled sensitivity to be high to justify draconian public energy policies. Disentangling the convoluted motivations in climate modeling, and indeed, in climate science as a whole, seems to me hardly worth the effort. Better I think to just cut most public funding of models and accept empirical studies as the basis for public policies. Too much politics in science makes for both bad science and bad politics.
stevefitzpatrick,
I’m not clear that they are “crazy-high in sensitivity”, or even what that means as a comparison of values.
This blog stays away from imputing motives to people.
If there was just an overwhelming desire to make everything “worse than we thought” then you wouldn’t expect (just as an example) this paper, Missing iris effect as a possible cause of muted hydrological change and high climate sensitivity in models, Thorsten Mauritsen and Bjorn Stevens, Nature Geoscience 2015. Here is an extract:
This paper isn’t some outlier. And why did Nature publish it?
Earlier in this thread another commenter highlighted van Oldenborgh et al. 2013 which highlights that models are over-confident via reviewing how often the observations in a grid cell are above the 95% of models spread and below the 5% of model spread (see my comment above). van Oldenborgh is a lead author for chapter 11 of AR5 (working group I).
The two papers cited in this article ask difficult questions.
If you read press releases in the media and follow certain blogs then you might conclude that all climate scientists are pressing forward into “more alarm”.
If you read 100s of climate science papers you will conclude something different.
I recommend reading lots of papers to ascertain what climate scientists actually say in climate science papers.
SoD,
“I’m not clear that they are “crazy-high in sensitivity”, or even what that means as a comparison of values.”
To me, “crazy high” sensitivity is anything over 4C per doubling, since that is grossly inconsistent with empirical estimates. Those “crazy high” sensitivity values appear unsupported by anything except a few models and paper based on arm-wave speculation about glacial/interglacial changes in temperature versus changes in global average albedo. An even simpler way to ascertain “crazy high” is to look at the individual model spreads over multiple runs to estimate the likelihood of each model encompassing measured warming over the past 40+ years. When measured reality falls outside the 95% inclusive range for repeated runs of an individual model, then that model is “crazy high” in sensitivity, as many clearly are. I ask always why models which clearly fail the most important test of credibility are neither modified nor discarded. I have never heard a reasoned reply. Of course, when a modeling group submits only a single run to the CMIP archive (as some do), then it is impossible to even judge if the model makes any sense, since you can’t estimate standard deviation from a single run. Those models should simply be discarded as scientifically meaningless. When a model shows a glaring “hot spot” in the tropical troposphere, and none is observed, then that model should be modified or discarded. It doesn’t happen.
“I recommend reading lots of papers to ascertain what climate scientists actually say in climate science papers.”
I have read lots of climate science papers over the past 10+ years, ranging from careful studies by folks like Bjorn Stevens (no coincidence, his PhD adviser was skeptic Richard Lindzen), to wild eyed speculation by folks like Stefan Rahmstorf and his associates about catastrophic sea level increases (eg 1 to 2 meters by 2100). I am underwhelmed by the literature, and political bias seems to me the only reasonable explanation for its poor quality.
(Serious aside: Do you honestly believe there is not a strong ‘green’ political influence among those who practice climate science? Do you honestly think that people with strong ‘green’ political beliefs are not susceptible to bias due to those beliefs?)
.
Real progress in understanding seems to me non-existent in the field: the Charney report in 1979 gave a likely range of sensitivity of 1.5C to 4.5C per doubling of CO2, and AR5 declared the same likely range….. 35 years of international research effort and tens (or hundreds!) of billions of dollars of taxpayer funding, all to conclude what Charney had concluded in 1979 at near-zero taxpayer cost. This is not like any science I am familiar with; it is closer to the aftermath of Roe v Wade in 1973, where people today are no closer to agreement than in 1973. That is the nature of political disagreements, not scientific ones.
But if I am wrong about climate science not being ‘normal science’ and you are right (that is, it is a science that is “self correcting” when wrong) surely responsible folks like Bjorn Stevens should step up and offer interviews with MSM outlets to explain that there is considerable uncertainty in the projections of doom by the models. Yes “serious scientists” like Stevens can publish papers which point out flaws in the models, but they dare not take the debate public, or they will suffer the political consequences.. Those serious scientists might also point out in the MSM that projections of catastrophic sea level increases by 2100 are almost certainly and comically wrong. They do not do that, because it would damage their careers, as Roger Pielke Jr, Judith Curry, and others have learned.
It is good to read published articles. It is even better to evaluate the field as a whole based on the same criteria other most other science is based on: what scientific progress has been made relative to taxpayer expense? My answer: essentially none that matters. Public de-funding is the most reasonable political response to what seem to me fundamentally a political disagreement.
I rescued Steve’s Nov 21 comment from the filter, so people won’t have seen it until now (Nov 24).
As explained in Comments & Moderation let me know if comments don’t make it through, WordPress has its own ideas.
The paper in Climate Sensitivity – Stevens et al 2016 also seems to think that 4.5K is very high. I wanted to get the value you believed was crazy high.
Papers I read acknowledge this problem and how serious it is. You think science shouldn’t try? Climate is a hard problem. This is where I believe my article The Debate is Over – 99% of Scientists believe Gravity and the Heliocentric Solar System so therefore.. has relevance. The questions about how sensitive climate is, how reliable models are and so on are essentially value judgements unrelated to the core questions of atmospheric physics.
There’s science and there’s politics and the media. What people publish tell you something about their science work – and that tells me the hard questions get asked. What gets reported in the media is just some strange world unrelated to reality.
Plus, you might have a family to feed and trying to “straighten out” media bias in any field, even a simple one, is a task for a special kind of person who has some (mistaken) idea the media gives a hoot about “reality”.
SoD,
Let me offer a concrete example: my company makes laboratory instruments which measure the size distribution in fine particulate materials, down to single nanometer size in many cases. So the instruments are often used by people working in ‘nanotechnology’ applications. There is already a significant political push by (no surprise) greens in Europe to institute regulations restricting the development and use of ‘nanomaterials’, demanding ‘zero risk’ for humans and the environment. It is all scientifically laughable (nanomaterials are everywhere in nature!), but the potential costs for those regulations is large and pointless. If this madness metasticizes beyond Europe, I will do everything I can to ‘set the record straight’.
Whether it is climate change, GM plant/animals, nuclear power, nanomaterials, or other subjects, greens politics is costly and damaging… and it seems to me pervasive in climate science.
SoD,
Thanks for liberating my comment. I had an error in that comment: Bjorn Stevens studied under William Cotton at Colorado, not Lindzen at MIT.
WRT misrepresentations in the MSM, I think responsible people working in any field, and especially one that is publicly funded, have an obligation to set the record straight when there are gross misrepresentations of factual reality…. like the endless Photoshop images of New York City under 30 meters of water, with a caption like “After Antarctica melts”….. being used to advance green political goals.
SOD and Steve, I think the issue here is that there are always choices to be made in terms of data selection and parameter selection. It seems to me that there is generally a tendency in climate science to select data and tune parameters to make things seem more serious. Just look at Steve McIntyre’s recent post on models vs. temperature data to see what I mean. He illustrates how the choice made can lower the GCM rate of temperature change by a large amount and bringing it down to where the data is. And then he shows how another data selection gives a hugely lower data rate of change.
This problem is seen most clearly in Mann’s original work where it almost seemed as if a non-standard statistical method was developed specifically to generate the desired result. The whole field of paleo-climatology is an example of how very uncertain data can be “processed” to agree with pre-conceived notions about CO2 as THE control know. It seems to me that we are still a ways from understanding the ice age cycle changes and their causes. Those were huge changes.
This issue infests a lot of science. It is very common in CFD where data is “selected” to make the authors and their methods/codes look good. This is classical selection bias.
I forgot to mention “consensus enforcement” which is a powerful mechanism to intimidate people and scientists who might have doubts. The problem here is more the non-scientists like Joe Romm who are basically political operatives of the same ilk as Fusion GPS, who become experts at intimidation. But there are some scientists who do this too. Mann is pretty abusive in his pronouncements about fellow scientists who he disagrees with.
This graph shows the global average near-surface temperature from the model with the highest diagnosed ECS in CMIP5 against observations. What basis is there for certainty that the model sensitivity needs to be revised? (Note there is a ~0.1K/Century positive trend in the model control run so the end of the series shown is about 0.15K warmer than a more proper comparison).
What I suspect you mean by ’empirical’ here is specifically studies using simple energy balance models of climate. There are other forms of empirical study which point to the high end of the model range. The big question (though there are others) for simple energy balance studies is why we should trust a one line equation to provide a completely accurate model of global average climate? Absolute trust in such accuracy is a fundamental untested assumption in all those studies. Our only means to test that assumption is through climate models, and several studies have found important non-linearities which suggest energy balance results don’t take into account highly important structural uncertainties. Which demonstrates the value of climate modelling working in conjunction with simplistic empirical approaches.
It seems to me that the willingness to unquestioningly accept and promote certain empirical (e.g. energy balance) results above all others has been dependent on the magnitude of the result, which suggests that the idea empirical = apolitical is not correct.
paulskio,
From what I can find in AR5, MIROC uses very large negative direct and indirect aerosol forcing to largely cancel out the greenhouse gas forcing to date. That allows them to get good agreement with the historical record in spite of a high sensitivity. But satellite data now constrain the aerosol forcing to much smaller values than used in MIROC. So the good agreement of MIROC with observational temperature seems to be all tuning without predictive value.
The early empirical studies were simple energy balance models, but much more sophisticated ones have since been done, with the same result. A simple model, if based on fundamentals, can often give a more trustworthy result than a more complex model that depends on a lot of tunable parameters. The complex models seem to confirm the basic validity of the simple energy balance approach.
But satellite data now constrain the aerosol forcing to much smaller values than used in MIROC.
Can’t see where you’re getting that from. According to the MIROC-ESM write-up aerosol forcing in the model is -1.1W/m2 relative to 1850. It will probably be a bit more negative relative to 1750 but still close to the IPCC central estimate and well within uncertainty ranges of studies using satellite data.
Whether or not it’s tuned is kind of irrelevant for this question when all the “choices” are plausible.
The complex models seem to confirm the basic validity of the simple energy balance approach.
But that’s essentially the rub of it though. The simple models gain their validity through approximately emulating complex models, and the fact that responses in complex models tend to be roughly linear. So it doesn’t make any sense to then completely ignore the complex models when it turns out ‘approximately’ and ‘roughly’ aren’t good enough if you want to accurately constrain climate sensitivity.
paulski0,
Well, the actual AR5 best estimate for net aerosol offsets (primary and secondary) was 0.82 watt/M^2. The majority of that (0.55 watt/M^2) is described by AR5 as a “low certainty” secondary cloud effect, and indeed, the uncertainty range for that secondary effect covers from 1.33 o 0.06 watt/M^2. In fact, this presummed secondary effect is the ONLY major forcing which is described by AR5 as having “low confidence” (see figure SPM5).
Any meaningful constraint on climate sensitivity will not come from climate models (any more than understanding the universe will come from gazing at your own navel), it will come from eliminating most of the uncertainty in secondary aerosol offsets.
BTW, simple models gain their validity not by emulating complex models, but rather by being congruent with reality… as all valid models must be.
What’s interesting to me is where all the above models appear to succeed:
global warming means reduced temperature extremes.
Though the spatial distribution differs, this is true of the seasonal variation ( increased winter temperatures and comparatively little change in summer temperatures ).
This has long been modeled. Arctic sea ice acts out of phase with seasonal variation: melting takes up heat in summer, and increased freezing releases latent heat in winter.
In general, yes I think, though there are some notable exceptions like Western Europe, where Winter temperatures are expected to warm slower than Summer, generally attributed to AMOC slowdown.
Interestingly the opposite effect is visible in Extratropical NH SSTs – a very clear seasonal cycle has appeared in anomalies, with Summer warming faster than Winter. Presumably related to the strong Winter warming on land, through some sort of land-sea flux?
paulski0,
Don’t confuse the overturning circulation with the oceanic gyre. The Gulf Stream, part of the North Atlantic Gyre, is driven by winds, specifically the northern hemisphere trade winds, not the overturning circulation. If the overturning circulation stopped, the Gulf Stream would still flow.
[…] an excellent paper by Frederic Hourdin and a number of co-authors. It got a brief mention in Models, On – and Off – the Catwalk – Part Six – Tuning and Seasonal Contrasts. One of the co-authors is Thorsten Mauritsen who was the lead author of Tuning the Climate of a […]